
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- lambda
- concat
- 표본분포
- 표분편차
- 표본
- 프로그래머스
- rrule
- datediff
- floor
- truncate
- pivot table
- Recursive
- merge
- calesce
- 데이터 리터러시
- 날짜함수
- 모집단
- 재귀쿼리
- split
- 정규분포
- append
- python
- 재퀴쿼리
- dateofmonth
- DATE_FORMAT
- 표준오차
- 신뢰구간
- curdate
- join
- limit
- Today
- Total
hyezdata 님의 블로그
[통계학 기초] 03 유의성 검정 본문
1. A/B 검정
- A와 B 중 어느 것이 효과적인지 평가하기 위해 사용하는 방법이다.

stats.ttest_ind
- 독립표본 t-검정을 수행하여 두 개의 독립된 집단 간의 평균 차이가 유의미한지 평가한다.
- 두 집단의 데이터 배열을 입력으로 받아서 t-통계량과 p-값을 반환한다.
- t-통계량 (statistic) : 두 집단 간 평균 차이의 크기와 방향
- p-값 (pvalue) : 귀무 가설이 참일 때, 현재 데이터보다 극단적인 결과가 나올 확률, 유의수준(α) 보다 작으면 귀무 가설을 기각하고 이 값이 유의수준(α) 보다 크면 귀무 가설을 기각하지 않는다.
2. 가설 검정
- 표본 데이터를 통해 모집단의 가설을 검증하는 과정
- 데이터가 특정 가설을 지지하는지 평가하는 과정
- 귀무가설과 대립가설을 설정하고 둘 중 하나를 택한다.
- 확충적 자료분석 : 미리 가설을 세운 다음 가설 검증
- 탐색적 자료분석 : 데이터를 탐색해보고 가설 을 세운 뒤 데이터 특징을 찾는 것
- 귀무가설과 대립가설 설정 → 유의수준(α) 결정 → p-값과 유의수준 비교 → 결론 도출
1) 통계적 유의성과 p값
통계적 유의성 : 결과가 우연히 발생한 것이 아닌 어떤 효과가 실제로 존재함을 나타내는 지표
p값 : 귀무가설이 참일 때, 관찰된 통계치가 나올 확률, 유의수준(0.05)보다 작으면 귀무가설을 기각하고 0.03이면 우연히 이런 결과가 나옴
2) 신뢰구간과 가설검정
둘 다 데이터의 모수(평균 등)에 대한 정보를 구하고자 하는 것이지만 접근 방식이 다르다.
신뢰구간은 특정 모수가 포함될 범위를 제공하고, 가설검정은 모수가 특정 값과 같은지 다른지 테스트 하는 것
3. t 검정
- 가설 검정의 대표적인 검정으로, 두 집단 간의 평균 차이가 통계적으로 유의미한지 확인하는 검정 방법이다.
- 독립표본 t검정 : 두 독립된 그룹의 평균을 비교한다. (ex. 두 클래스의 시험 성적 비교)
- 대응표본 t검정 : 동일한 그룹의 사전/사후 평균을 비교한다. (ex. 다이어트 전후 체중 비교)
4. 다중 검정
- 여러 가설을 동시에 검정하는 것
- 그러나 1종 오류가 발생할 수 있다. (귀무가설이 참인데 기각하는 오류)
- 본페로니 보정, 튜키 보정, 던넷 보정, 윌리엄스 보정 등을 통해 오류를 보정할 수 있다.

본페로니 보정을 통해 0.05보다 더 낮게 만들어서 오류를 줄인다.
5. 카이 제곱 검정
- 범주형 데이터 분석에 사용한다.
- 표본 분포가 모집단 분포와 일치하는지 검정(적합도 검정)하거나 두 점주형 변수 간의 독립성을 검정(독립성 검정)하는데 사용하나.
- 적합도 검정 : 관찰된 분포와 기대된 분포가 일치하는지 검정하는 방법으로, p값이 높으면 귀무가설, 낮으면 귀무가설과 맞지 않음을 뜻함
- 독립성 검정 : 두 범주형 변수 간의 독립성을 검정하는 방법으로, p값이 높으면 두 변수 간에 연관성이 없고(=독립성이 있음), 낮으면 연관성이 있음(=독립성이 없음)을 뜻한다.
- ex. 주사위의 각 면의 확률(적합도 검정), 나이와 직업 만족도간의 독립성 검정

stats.chisquare
적합도 검정에 사용하는 함수로, 관찰된 빈도 분포가 기대된 빈도 분포와 일치하는지 평가한다.

stats.chi2_contingency
독립성 검정에 사용하는 함수로, 두 개 이상의 범주형 변수간의 독립성을 검정한다.

6. 제 1종 오류와 제 2종 오류
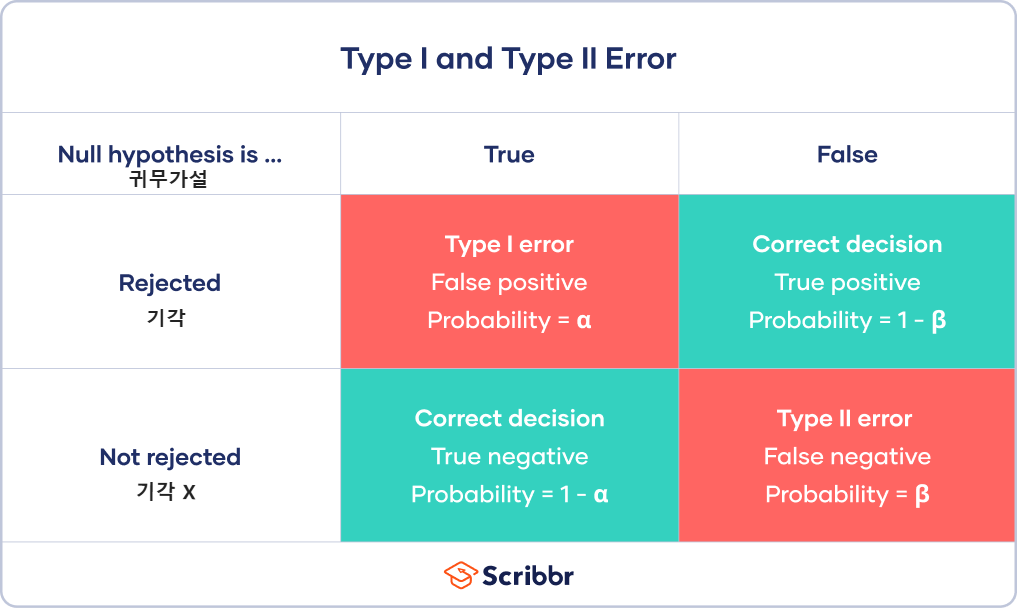
1) 제 1종 오류
귀무가설이 참인데 기각하는 오류로, 위 그림에서 TYPE 1 ERROR에 해당한다. (위양성; False positive)
아무런 영향이 없는데 영향이 있다고 하는 것!
오류가 유의수준(α) 만큼 발생한다. 따라서 유의수준(α)를 정하면 제어가 가능하다.
(α가 제1종 오류가 나타날 확률이라면 α를 낮출수록 제1종 오류가 나타날 확률이 줄어든다.)
2) 제 2종 오류
귀무가설이 거짓인데 기각하지 않는 오류로, 위 그림에서 TYPE 2 ERROR에 해당한다. (위음성; False negative)
영향이 있는데 영향이 없다고 하는 것!
제 2종 오류가 나타날 확률을 β라고 하며, 직접 통제할 수 없고, 표본크기나 α를 통해 통제할 수 있다.
왜냐하면 α와 β는 상충관계에 있기 때문
(표본크기 n이 커질수록 β가 작아짐, α가 낮아지면 β가 높아짐)
'내일배움캠프 > 데이터 강의' 카테고리의 다른 글
| [통계야 놀자] 1회차 (0) | 2025.04.02 |
|---|---|
| [통계학 기초] 04 회귀 (0) | 2025.04.02 |
| [통계학 기초] 02 데이터의 분포 (0) | 2025.03.31 |
| [통계학 기초] 01 데이터 분석과 통계 (0) | 2025.03.31 |
| [데이터 리터러시] 5강 결론 도출 (0) | 2025.03.04 |


